
1 AIの技術開発における現状と動向
(1) 激化する世界のAI開発競争
AIには様々な形態のものがあるが、昨今のAI技術開発や応用において大きな潮流となっている分野の一つが、文章や画像、動画等を生成する「生成AI(generative AI)」であり、その技術の一つが、深層学習技術を応用した大規模言語モデル(LLM:Large Language Model)である。2020年にOpenAIによって、学習に使われるデータの規模・学習に使われる計算量・モデルのパラメータ数が増加すればするほど、LLMの性能が向上するというスケーリング則(Scaling law)が提唱された。例えば、OpenAIが2019年に発表したモデルであるGPT-2のパラメータ数が15億だったのに対し、同社が2020年に発表したGPT-3のパラメータ数は約120倍の1,750億まで大規模化した。その後も大規模化の波は止まらず、2022年4月にGoogleが発表したPaLMのパラメータ数は5,400億まで及んでいる(図表Ⅰ-1-2-1)。
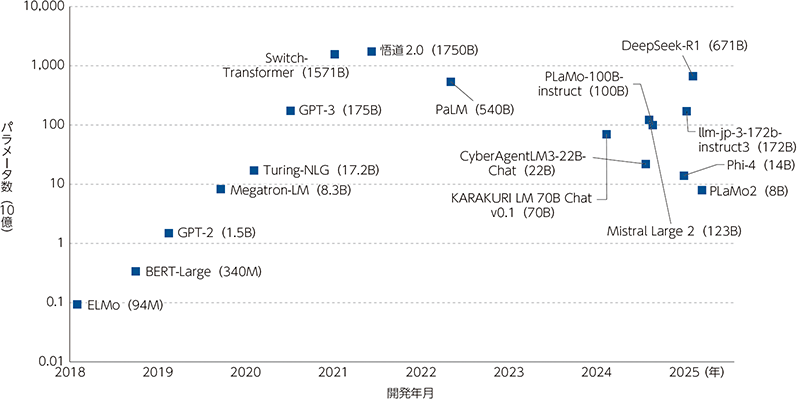
スケーリング則に従い、ビッグテック企業を中心に、計算資源であるGPUや、データセンターへの投資が激化した。また、ビッグテック企業やベンチャーキャピタル等から巨額の投資を受けた、OpenAIやAnthropic、Mistral AIといったスタートアップ企業等も、LLM開発において主要な担い手となり、開発競争に参加している。
【関連データ】主要なAI開発事業者の投資状況
URL:https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r07/html/datashu.html#f00028![]() (データ集)
(データ集)
1 本図には、パラメータ数が公表されていないモデルは反映していない。最近の大型LLMはパラメータ数が非公表の場合が多いことに注意。