
(4)日米のICT人材の比較
我が国でICT利活用によるイノベーション促進及び付加価値増加を目指すにあたり、現状では、ユーザ企業にICT人材が少ないという構造的問題があることについて補足する。
我が国は米国と比較して、ICT人材の数が少なく、さらに人材がユーザ企業側に少なくベンダ側に偏在している傾向がある。独立行政法人情報処理推進機構の「IT人材白書2017」では、2015年の日米の情報処理・通信に携わる人材数を推計している(図表1-4-1-7)。
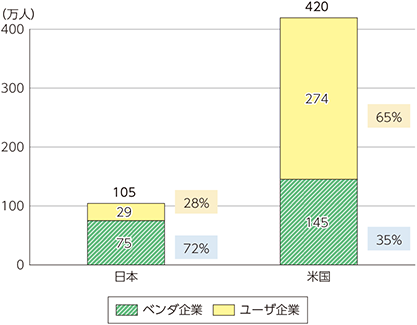
これによると、情報処理・通信に携わるICT人材は日本では105万人、米国では420万人であり、日本は72%がベンダ企業16に属する一方、米国は65%がユーザ企業に属する。ただし、我が国は雇用慣習の違いから人材の流動性が低い点は留意が必要である。
「はじめに」でも述べたように、今後、IoT、AI等によってICT技術がますます高度化すると共に、さまざまな領域でデジタルデータが活用されるようになる。企業側の視点でみると、自社のビジネスモデルのコアの部分とそれ以外の部分とを見極め、それぞれにデジタルデータを上手く活用することが、競争力や付加価値増加のためにも必要になる。
ここで自社開発17が重要となってこよう。自社開発は委託開発と比較して社内で迅速かつ柔軟に対応できる、社内の事情や目指す戦略を共有しやすく、システム開発や自社のデータ活用に関しても開発側から攻めの提案が行いやすい18などの利点があり、これらはイノベーション実現や付加価値増加にもつながると考えられる。
総務省情報通信審議会が2017年1月に公表した「IoT/ビッグデータ時代に向けた新たな情報通信政策の在り方について第三次中間答申」では、「IoTが社会に実装され、社会インフラとして機能していくためには、システムの構築・管理・運用を担う人材の育成が急務となる。」旨述べ、概要資料中でも「グローバルに競争するIoT時代を迎え、今後10年間(〜2025年)で、ICT企業中心の「日本型」からユーザ企業中心の「米国型」への転換を図り、最大200万人規模のICT人材の創出と、最大60万人規模の産業間移動を実現することが必要。」としている。
コラムCOLUMN 1 実装の進むAI・IoT概説
近年、様々な分野で、「AI(人工知能)」、「IoT(モノのインターネット)」が実装され始めており、今後は、社会・経済に大きなインパクトをもたらすと期待されている。白書本文では、AI・IoTが頻繁に登場することから、ここでは、それらについて、これまでの発展の経緯や現状などを簡潔に説明する。
1 特定の分野では人間以上の“判断”が可能になったAI(人工知能)
AIとは、「Artificial Intelligence」の略で、日本では「人工知能」と訳される。一般的なイメージとしては、「人間に代わって計算したり判断したりできる高性能なコンピューター、または、そのためのソフトウェア」や「知能があるかのように振る舞える人工物」といったものが拡がっている。だが実は、AIの明確な定義はない。「知能」の定義が難しい現状では、それを人工的に実現することの定義も難しい。
にもかかわらず最近は、様々な分野で「AI」のキーワードが目立つ。しかし実際には、そのいずれもが人に備わる機能の、ごく一部分を実行しているに過ぎない。AIスピーカー(スマートスピーカー)で使われている音声認識や、スマートフォンのロック解除にも搭載された顔認識などは、AIの一部ではあるが、すべてではない。またAIスピーカー(スマートスピーカー)では、私たちが日常的に話している文章を認識し、検索したり、その結果を表示/再生したりするためには、音で得られた文章の構造や文脈を含めて処理しなければならない。こうした自然言語をコンピューターに適切に処理させるための技術を自然言語処理と呼び、同分野の精度向上にもAIが適用され始めている。
音声認識や顔認識など、特定の分野でのAIはすでに人間と同等の認識率を実現している。19そうした現象をみて「AIは万能だ」と感じている人々は多いし、「AIが人間の仕事を奪ってしまう」といった論調も少なくはない。人間を置き換えるほどに万能なAIを「汎用AI」と呼ぶが、この領域に至るには、まだまだ研究すべきことが多く、その実現手法を探っているのが実状である。これに対し、音声認識や画像認識など特定の機能をこなすAIは「専門AI」と呼ぶ。
また、汎用AIと専門AIの対比を、米国の言語哲学者John Searle氏が「強いAI」と「弱いAI」と呼んだことから、AIと人間の能力を比べる際には、AIの能力を「強い」「弱い」と表現することもある。現時点でAIと称している仕組みは、この弱いAIであり、各種研究の進展に伴って実用化が始まっている段階である。
(1)機械が学習することで“判断”を実現
その意味で、現在「AI技術を使って実現」と表現されていることの多くは、実際には「大量のデータに潜む特徴(パターン)を見つけ出す技術である機械学習による“判断”の実現」を指している。専門的には、分類や、回帰、クラスタリングなどの実現と呼ばれるが、これらに共通する概念は“線引き”であり、ここでは、これらをまとめて“判断”と表現しよう。
機械学習で実現する判断とは、データを機械、実際にはソフトウェアに読み込ませ、その属性を自動的にふるい分けられるようにすることである。学習したソフトウェアは、未知の入力に対しても適切にふるい分けられるようになる。もちろん、未知の入力に対して誤った結果を出すこともある。その場合は、新たなデータを使って学習を進めることで、ふるい分けの精度を高めていく。
学習の手法には、「教師あり学習」や「教師なし学習」「強化学習」などがある。教師あり学習とは、入力するデータと、結果に対する正解を与える手法だ。教師なし学習は、入力だけを与える手法であり、強化学習は、判断の結果によって与えられる“報酬”が、より高くなるように学習していく手法である。
機械学習の実現方法もさまざまである。それらの中で近年、最も利用されているのが、「ニューラルネットワーク」である。ニューラルネットワークは、1958年に米国の心理学者Frank Rosenblatt氏が発表した「パーセプトロン」を源流とする。パーセプトロンは、神経の動作を真似るモデルで学習ができる。これを何層にも重ねて接続し、人の神経網を真似たのがニューラルネットワークである。
ニューラルネットワークは、 1960年代と1980年代に、2度ブームを迎えており、現在は3度目のブームにあると言える。1990年代と現在の違いは、多層化の度合いである。かつては数層だったものが、現在では200層を超えることもある。
多層化が進んだニューラルネットワークを利用する実現方法を「深層学習(Deep Learning:ディープラーニング)」と呼ぶ。深層学習にも複数の接続方法や学習方法があり、深層学習という1つの方式があるわけではない。
(2)深層学習により音声認識と画像認識が劇的に改善
深層学習は、2011年に音声認識の分野で、2012年には画像認識の分野で、それぞれの認識率に劇的な改善を見せた。
それまでの機械学習では、入力情報のモデルを作り、見つけるべき特徴を抽出させ、そこから得る特徴量を人間が設計していた。
これに対し深層学習では、判断用のモデル自体を自動で学習する。ただし、与えるデータによって生成されるモデルが変化するために、どのようなデータを与えるかには考慮が必要である。また結果のみが得られる形になるため、深層学習による判断理由を提示するための研究も行われている。
深層学習を中心としてAIは、その仕組みから、人で言う“経験と勘”を置き換えているといえる。データによる機械学習が“経験”であり、経験の蓄積による判断が“勘”である。これまで“経験と勘”に頼ってきた作業は、AIに置き換えられると考えられる。ただし、記憶をたどり新たな発想を展開する作業は、現在のAIには実行できない。
(3)AIの精度を高めるには、良いデータとハードウェアが必要
深層学習によるAIは現在、認識率が高まった画像認識や音声認識などのアプリケーションとしての利用が広がっている。画像認識のAIは、顔の認識だけでなく、表情の認識や身体の動きの認識などにも使える。これを医療分野に応用し、X線画像から病変を発見するといった用途にも利用されている。
深層学習に限らず、機械学習で注意しなければならないことは、学習に使うデータの質である。典型的なデータのみを集めていては、よい判断ができないし、不適切なデータからは不適切な判断を下すことになる。学習データの質が、深層学習の成果を左右する。
また深層学習の学習と実行には、コンピューターの強力な処理能力が必要になる。ソフトウェアによる処理では時間がかかるため、ハードウェアによる高速化支援が欠かせない。
これまでのハードウェア支援策としては、画像処理用に設計されたGPU(Graphics Processing Unit)による加速が一般的だった。深層学習における計算は行列計算であり、これを並列に実行する。一方のGPUも、数式で表された画像(行列など)に対する計算を並列実行することに最適化されている。両者のアーキテクチャーの合致により、深層学習の実行速度はGPUにより高速に実行できている。
それが最近は、深層学習の加速機能をシステムLSI(SoC:System on a Chip)に組み込む動きが始まっている(図表)。スマートフォン用のシステムLSIにも、深層学習の加速機能を搭載したものが登場している。機械学習による判断が半導体に組み込まれていくことで、AIは、より多くの場面で利用できるようになる。
2 IoTは「モノをつなぐ」から「社会を最適にする」に大きく変化
IoTとは、「Internet of Things」の略で、「モノのインターネット」と訳されることが多い。電車やクルマ、工場やビル、製造機械や飛行機のエンジン、冷蔵庫や洗濯機、農地や牧場の牛などなど、あらゆるものをネットワークに接続することで、それぞれの最新状態を示すデータを集め、その分析から、より最適な状態に導くようにフィードバックを返すという、一連の流れを指している。
ネットにつながるクルマを「Connected Car」と呼ぶなど、「Connected(つながっている)」ことで、新たな価値を生み出そうとする概念や取り組みだとも言える。スマートフォンや携帯電話は「Connectedな電話機」であり、内蔵するセンサーなどにより、私たち利用者の行動を把握できるIoTの一種である。最近は、スマートウォッチや活動量計といったウェアラブルデバイスの登場により、歩数や脈拍など私たちの身体の状態まで把握できるようになっている。
(1)もはやインターネットを前提としない
IoTは1998年に、米国マサチューセッツ工科大学(MIT)のDavid Brock氏とSanjay Sarma氏が提唱した用語である。もともとは、RFID(ICタグ)を使ってモノの個数や存在場所を1つひとつ正確に管理しようとする取り組みの中で、遠隔地にあるICタグを読み取るために発想された。ICタグを読み取る部分と結果を表示する部分を分け、両者をインターネットで結ぶという構想だったという。
この構想を起点に、「モノがインターネットにつながれば何が起こるか」が議論されるようになり、それを実現するための各種の技術が発展し、現在のIoTへとつながっている。現在のIoTは大きく、(1)モノの状態を把握するセンサー、(2)センサーで得たデータを集約するためのネットワーク、(3)集約したデータを蓄積・分析するためのサーバーあるいはデータセンター、(4)分析結果をモノにフィードバックするアクチュエーターで構成され、そのシステム全体を指すようになっている。
IoTと並列に使われる用語に「M2M(Machine to Machine)」がある。機器と機械の間の通信を意味し、機械同士が通信する状況を示している。厳密にはM2MはIoTの一要素であり、それ自体はIoTではない。IoTと呼ぶには、上記のように一連のシステムが成り立ち、状態の最適化を目指す必要がある。もっともM2Mを使ったアプリケーションは、この条件に当てはまるため、アプリケーションを含めたM2MがIoTと同義に使われている。
現在のIoTは、ICタグの読み取りといった固定的な情報の伝達を目指してはいない。世の中に存在する、さまざまな情報を集め、それを処理することで最適化を図るというシステム的な発想が組み込まれている。無線の通信環境の普及や、サーバーやデータセンターも昨今はクラウドに変わり、IoTに特化したサービスの提供も始まっている。センサーの多様化も進む。「インターネット」の名前が冠されるが、もはやIoTというシステムとしては、いわゆるインターネットを使う必要もない。
(2)リアルな社会を写し取った「デジタルな双子」をAIで分析
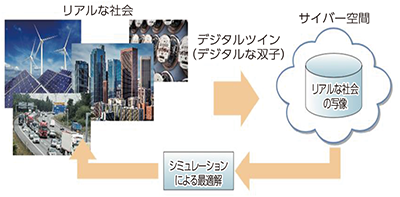
モノの管理から、データに基づきさまざまな事象の最適化を図るというシステム思考に発展したIoTは、「CPS(Cyber Physical System)」とも呼ばれる。リアルな社会の状況を、種々のデータによってネット上(サイバー空間)に再構築し、そのデータを分析することで、まずはサイバー空間上で解決策をシミュレーションし、最適なものをリアルな世界に反映させるという概念である。
このとき、リアルな社会とサイバー空間に構成されるビッグデータを「デジタルツイン(デジタルな双子)」と呼ぶ。それぞれで起こっていることが相互に反映されることで、両者は常に“双子”のように存在し、影響し合い、さらには両者の融合が始まり、その境界線はあいまいになっていくと考えられている(図表)。VR(仮想現実)/AR(拡張現実)などは、こうした考えを視覚面で実現した仕組みだと言える。
デジタルツインの構築・活用において、研究開発が盛んになっているのが、データ収集のためのセンサーと、データを分析するためのAI(人工知能)である。センサーは、測定したい対象の広がりや欲しいデータが明確になってくるのに合わせ、新たなセンサーや、複数のセンサーを組み合わせた複合的な測定装置などが登場してきている。
一方のAIは、IoTの考えに沿って、より多くのデータが集まり保存されるようになったことから、機械学習/深層学習の精度が高まっている。機械類の故障を事前に感知する予測機能や、将来の需要予測などが主な用途である。
なかでも急速に適用例を増やしているのが画像認識のAIである。カメラで撮影した静止画や動画を分析することで、個々人を判別したり、一定エリアにいる人の数をカウントしたり、あるいは小売店で商品を手に取ったのかどうか、何をバッグに入れたのかといったことの判定にも利用できる。これらの認識機能を使って、商品だけが並び店員が一人もいない「無人店舗」も登場している。
(3)デバイスやセンサーの増加を支えるネットワークが課題に
加えてIoTで注目されているのがネットワークである。工場内などであれば無線LANを使えば一応の通信はできる。しかし今後、IoTが発展していくと、これまでの無線LANでは足りなくなる。数の問題と距離の問題が発生するためである。
数の問題とは、接続すべきIoTデバイスやセンサーが増えることである。デジタルツインをより精密にしようとすれば、各種センサーを至るところに設置することになる。現在の無線LANは、一定エリアに数千ものデバイスやセンサーが置かれることは想定されておらず、円滑な情報伝達が維持できなくなるかもしれない。
一方の距離の問題とは、製品の生産から物流、販売、客先での利用と保守までのライフサイクル全体をカバーしようとすれば、長距離な通信が必要になる。長距離通信では、無線LANではなく、携帯電話用(セルラー型)の無線方式が使われている。だが第4世代(LTE/LTE-Advanced)までは、地域によって採用されている方式が異なり、それぞれへの対応が必要である。
対策は進んでいる。数の問題では、2017年7月に規格化された「IEEE 802.11ah(Wi-Fi HaLow)」のように、8000台もの端末が利用できる無線LANが登場する。第5世代(5G)では1キロ平方メートル内で100万端末の運用を目指す。
距離の問題は、セルラー型の無線方式の中では、「NB-IoT」や「LTE Cat-M1」などIoTに最適化した方式が登場している。これまでのように高速化を指向するのではなく、数への対応や通信距離の拡大、および低消費電力化を図っている。1日1回、数百バイトのデータを送るだけでなら、単3乾電池2本で10年間、通信できるように設計されている。
長距離(数キロから数十キロメートル)、低消費電力に的を絞ったIoT用の通信方式も広がり出している。LPWA(Low Power Wide Area:低消費電力型長距離無線通信)あるいは非セルラー型LPWAと呼ばれる方式で、フランス発の「Sigfox」や、Ciscoをはじめとした米国企業や業界団体が推す「LoRaWAN」がある。いずれも免許が不要な無線帯域を使う。ただし、データ通信速度は、数十ビット/秒から数百kビット/秒である。
コラムCOLUMN 2 エストニアの事例
1 政府機能の電子化が進むエストニア
バルト3国の一つであり、人口がわずか約130万人の国であるエストニアは、インターネット電話サービスのSkypeを始めとするさまざまな新規ICTサービスを生み出してきた国として知られている。同国では政府が率先して公共サービスの高度な電子化及びインターネットを通じた民間サービスとの連携を図ってきた。
「電子政府」とも表現されるエストニアの政府機能及び主要な社会制度を支えるのは、全国民に対して割り振られる国民ID番号である。このID番号を基にした、電子署名や電子認証機能を持つ「国民IDカード」、「携帯電話に挿入するSIMカード」、「スマートフォンやタブレット向けの専用アプリ」などを利用することで、エストニアの国民は個人情報を必要とする様々なサービスをインターネット上で利用することができる。また公共サービスの各部門及び各種の民間サービスはシステム上で連携しているため、エストニア国民はたった一つのID番号を用いて、選挙における電子投票(図表1)から、保護者による個々の学生の学習進捗状況の把握、犯罪者データベースへの照会、電子カルテとの連携といった様々な用途へと活用することができるのである。

こうした電子政府の仕組みを利用することで、例えばエストニア国民は法人登記をオンライン上にて20分以内で完了させることができる。また患者ごとの過去の医療情報を網羅した電子保険記録システムや電子処方箋システムとも連携されているため、医師による異なる病院間での特定の患者の治療記録の共有や、カルテや処方箋の記入など事務処理作業の効率化を実現している。さらには国民の95%がインターネットを通じた確定申告を行っており、生産年齢人口の90%がインターネット・バンキングを利用している20。
2 電子政府が誕生した背景
1991年にソビエト連邦より独立したことで独自の新規制度を構築する必要があったエストニアでは欧州の国としては比較的広い国土を有する一方人口が少なく(国土面積は日本の10%強であるのに対して人口は日本の約1%)、公共サービスを電子化することで業務効率化を図る必要があった。また、トップの大統領がITの専門家であることに加え、現行の政治家・役人の世代が非常に若いことが、電子政府の推進をさらに加速させた要因として挙げられる。
こうした背景を受けて、エストニア経済通信省が中心となり、様々なサービスの電子化を通じた公共部門の業務効率化を推進。近年では、2012年秋から2013年春にかけて行われた民間企業や公共セクターなどとの協議を踏まえて2020年までに実施すべき関連施策などをまとめた「デジタル・アジェンダ 2020」21などに基づき、ICT利活用のための環境整備を目指している。
同資料によると、エストニアにおける固定ブロードバンドのカバー率は2011年時点で93.9%、現在は2020年に完成予定の6500キロにわたる光ファイバーケーブルネットワークを整備中であり、全国民が30メガビット毎秒以上、6割以上が100メガビット毎秒以上のインターネットに接続することができる環境づくりを目指しているという。
なお、エストニアでは、国民のICT教育にも注力。2012年9月からは、政府関連組織である「タイガー・リープ基金(現・財団法人教育情報工学発達センター:HITSA)」を通じて、小学生から高校生までを対象とした全国的なプログラミング教育推進プログラムが開始されている。
3 データ交換基盤「X-Road」
IDカードやICT教育と並んで、エストニアの電子政府を支えるのが、各省庁やその他の機関のデータベースを連携させるためのデータ交換基盤「X-Road」である。このX-Roadを通じてあらゆる行政機関や医療機関などがシステムを連携させているため、国民の個人データに対して非常に広範囲な「紐付け」が実現されている。なお、エストニア政府は、国民や企業は政府機関に一度のみ自身の情報を提供すれば良く、同じ情報を複数の機関に提供する必要がない「ワンスオンリー原則(once-only principle)」22を方針としており、政府が提供する電子サービスの利便性が高まっている。
エストニア政府によると、X-Roadを活用することにより、年800年に相当する労働時間を節減23。この仕組みは国内の各システムとの連携に留まらず、2013年からは国外の諸国とも接続されることになった。エストニア政府は、このX-Road及び関連システムの構築に当たって、国内のIT企業6社に委託。政府自ら先進的なソリューションを導入することにより、ICT分野の産業育成にも貢献しているといえる。
4 データ危機管理
各種制度やサービスの電子化が進むに伴い、最も懸念されるのが、サイバー被害によるデータの喪失や災害時にインターネット利用が制限された際の対応策などである。エストニアは2007年にロシアからサイバー攻撃を受け、エストニア政府関係のものを含む58ものウェブサイトが一度にアクセス不能になる事件が起きた過去があるため、とりわけ危機意識は高い。
そこでエストニア政府が考えた解決策が、海外のデータセンターに政府が保有する公的データのバックアップを保管する仕組みとなる「Data Embassy(データ大使館)」の構築であった。この取組はルクセンブルグのデータセンターにおいて、2014年より試験運用が始まっている24。
5 電子国家エストニアの未来
エストニア政府は、充実したICT基盤の拡充を目的として、スマートグリッドや電気自動車充電ネットワークの構築にも注力している25。2018年からは国家規模でのブロックチェーン技術を通じたエネルギー取引の実証実験を開始した26。また人口が少ないという長期的な社会的課題を解決すべく、エストニアの非居住者を電子国民=仮想国民と位置付けるための「e-residency」の取組を2014年より本格的に展開し、2025年までに1000万人のエストニア仮想国民を誘致すると掲げている27。さらには政府が発行する仮想通貨「エストコイン」の構想も発表28するなど、国家規模での電子化に向けての取組は今後も積極的に行われていくと見込まれている。


4 日本との関係
2018年1月、安倍総理大臣がエストニアを訪問し、ラタス首相と首脳会談を行った。その場で両首脳は、サイバー分野での両国の協力を進めていくことで一致した。5月にはウルヴェ・パロ起業・情報技術大臣が来日し、野田総務大臣及び小林総務大臣政務官と会談を行った。本会談では、日・エストニア間のICT・サイバー分野での協力や、両国の電子政府に関する取組みについて意見交換が行われた。

16 ソフトウェア業、情報処理・提供サービス業、インターネット附随サービス業
17 多くのユーザ企業にとっては、自社で0から独自のものを構築するのではなく、OSやパッケージソフトを活用しつつ自社の競争や付加価値創出上必要な部分をカスタマイズすることが費用対効果の点でも効果的と考えられる。
18 委託開発では、劇的に費用を低下させる新技術があってもベンダにとってはその新技術を採用することは売上低下につながりかねない場合、新技術採用に伴うリスクを過度にベンダが負う場合には、新技術を採用することが全体最適であったとしても新技術が採用されない可能性がある。
19 MicrosoftやGoogleなどによると、音声認識率95%前後と、人間の認識率と同等あるいはそれを上回る結果が報告されている。
"Microsoft researchers achieve new conversational speech recognition milestone",Microsoft Blog(2017年8月20日)
https://www.microsoft.com/en-us/research/blog/microsoft-researchers-achieve-new-conversational-speech-recognition-milestone/![]()
20 デジタル・アジェンダ 2020
https://www.mkm.ee/sites/default/files/digital_agenda_2020_estonia_engf.pdf![]()
21 デジタル・アジェンダ 2020(20に同じ)
22 欧州公共部門ネットワーク
http://www.eupan.eu/files/repository/20171221145326_(5)_EUPAN__Once-only_principle__Janek_Rozov.pdf![]()
23 X-Roadを通じて照会、問合せ、手続等を行った場合は、従来の方法と比べ1件当たり15分が節約できると想定し、実際の件数を掛け合わせることで算出。
エストニア情報システムセンター
https://www.ria.ee/x-tee/fact/#eng![]()
24 E-estonia
https://e-estonia.com/estonia-to-open-the-worlds-first-data-embassy-in-luxembourg/![]()
25 e-Estonia guide
https://e-estonia.com/wp-content/uploads/eestonia-guide-2018.pdf![]()
26 Elering AS/WePowerプレスリリース
https://pr.blonde20.com/wepower-elering/![]()
27 E-estonia
https://e-estonia.com/e-estonia-state-of-the-future/![]()
28 E-estonia
https://e-estonia.com/were-planning-launch-estcoin-only-start/![]()
29 ツールボックス・エストニアより
https://toolbox.estonia.ee/media/1651![]()